Applications are moving to cloud-native Kubernetes-based platforms, come hell or high water, lift-and-shift as stateful apps or rewrite into a microservice design. Now what? The malware and threads follow the applications to these cloud native platforms. As the Tesla breach in 2018 showed, it was relatively easy for attackers to infiltrate the Kubernetes console, access privileged information and run custom workloads. Consequently, in this new environment, we have new vulnerabilities to detect and patch, new intrusion attempts to detect, and new remedial measures to undertake. While much of this can be achieved with a rigorous SecOps playbook, the detection of attackers or attacks is significantly harder.
Conventional detection schemes that monitor all activity to single out suspicious ones, however, are plagued with high false positives that overwhelm the administrators and false negatives in ignoring cleverly disguised attackers. The industry has found deception technology, or honeypots as they are more commonly known, as a much more effective mechanism for detection. The main idea of using deception technology to lure attackers is to mirror real applications, without affecting the real applications, in the production infrastructure. Once mirrored, we rollout out a copy, called a decoy, that no legitimate user should be accessing, and include references, called breadcrumbs, to lure in attackers to these decoys.
Rollout of decoys is incredibly hard to do in clouds; see for example the challenges in deploying a convincing AWS honeytoken that an attacker cannot expose as a fake. In the case of Kubernetes based workloads, it is considerably easier to deploy a convincing decoy workload for two reasons. First, we have plenty of information, captured within Kubernetes and Helm descriptors, about the production application and its dependencies that we intend to mirror; typical details found in these descriptors of an application include the pod name, service name, service ports, replication count, environment variables, and access privileges. These descriptors are easier to mirror, tweak and recreate, either within a new namespace or the existing production namespace. Second, many of the cloud native applications use open-source software (e.g., MongoDB, Jenkins, ElasticSearch) for which the descriptors and details are already available in public domain, making it easier to ensure the fidelity of the mirroring.
Let’s look at an example to better understand application mirroring for deception. We rolled out the guestbook app within a GKE Kubernetes cluster and adopted a 4 step process for introducing deception alongside it: 1) Discover, where we extract information about the cluster and the applications already running, 2) Deploy, where we design and deploy the effective decoys as pods and services, 3) Inject, where we deploy the breadcrumbs in the form of ConfigMap or Ingress entries, 4) Track, where we monitor the various accesses to the decoys from internal and external attackers, and raise appropriate alarms. The first three steps use the Kubernetes API, and the last step uses the Acalvio ShadowPlex system.
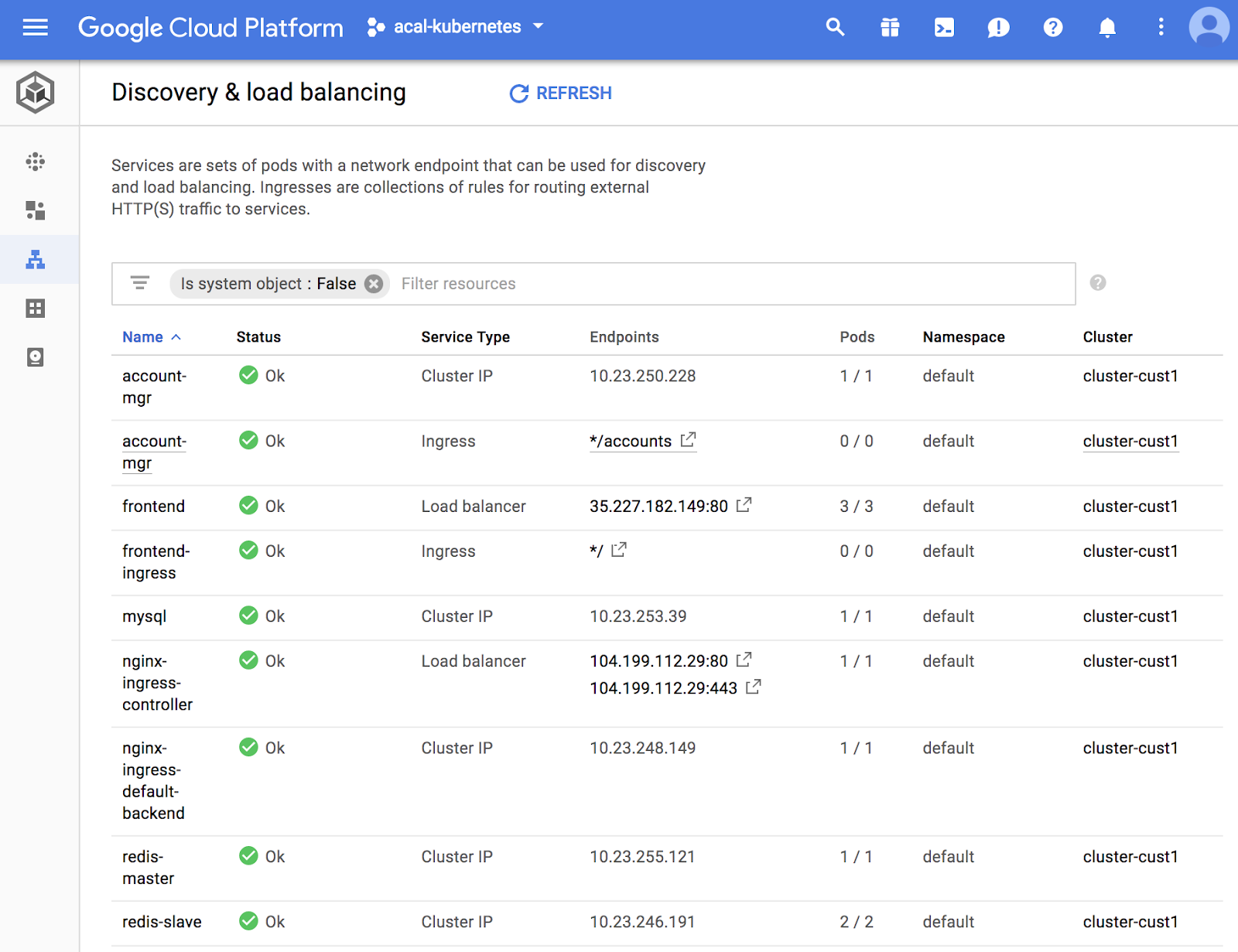
We show above a snapshot of the Kubernetes dashboard with the production services and decoy services deployed together. Can you spot the decoy entries? Like you, an attack will find it non-trivial to identify as fake our decoys (mysql and account-mgr pods and services) and breadcrumbs (account-mgr service and ingress entry). This is exactly what an effective deception looks like!
While we made it look easy, it is still challenging to tailor these deceptions to the environment and to detect attackers in real-time. Stay tuned for a follow up blog with more details on how we solve this for you!
Authors



